March 9, 1999
I did a bit of experimenting last night. After encountering a problem I was looking through my code trying to find the bug. As it turns out the problem was actually in my TIM. However, upon looking at my code I began wondering how much I could optimize it. One thing led to another and I ended up spending most of the night playing with optimizations. Bear with me, this'll be a long one.
I used the root counter to keep track of how long this function took to execute. Basically you poll the counter once at the beginning and then poll it again at the end, subtracting to get the time elapsed in rcnt ticks (you also need to adjust if the counter wrapped around in the meantime). You have to be extra sneaky, though, because the root counter is only 16 bits and wraps around really quickly. I had to poll it several times during the function to get an accurate count.
I should probably tell you a bit about the function. I wrote this routine a looong time ago. It's part of my menu routines and is responsible for printing a single line in a menu. Without going into too much detail, as I copy each letter over from the font TIM to the actual menu, I need to traverse each pixel of that letter and alter it (if you're really interested why, drop me a line). So this function had a loop for each row & column. To speed things up (and since what I'm doing isn't too complicated), I grouped 4 pixels together into a u_short (I'm using a 4-bit TIM so each pixel is only 4 bits). Thus the loop went something like this:
u_short buf1[16][4], buf2[16][4];
u_short val;
.
.
.
for (row = 0; row <= 15; row++)
for (col = 0; col <= 3; col++) {
buf2[row][col] &= val;
buf1[row][col] |= buf2[row][col];
}
You can see it's just traversing the rows and columns, performing the required operations. It's not necessary to understand exactly what it's doing.
Now, back to my debugging. While I was looking through this function I realized that using u_shorts was not the best way to do things. Since the Playstation has 32-bit registers, using only 16 bits is rather inefficient. However, I wondered if would actually see any speed up if I switched to u_longs. That's when I started using the root counter.
At the beginning of the function I added the following:
int rcnt, rcnt_old, rcnt_cum; StartRCnt(0); ResetRCnt(0); rcnt_cum = 0; rcnt_old = GetRCnt(0);
Then within the body of the function I placed this block of code:
// Poll root counter rcnt = GetRCnt(0); rcnt_cum += rcnt - rcnt_old; if ((rcnt - rcnt_old) < 0) rcnt_cum += 0xFFFF; // see if counter overflowed rcnt_old = rcnt;
Since the root counter increments very quickly I had to make sure I performed this operation often enough so it wouldn't loop around before I could poll it again. With that in place I added the following to the end of the function:
// Check counter one last time
rcnt = GetRCnt(0);
rcnt_cum += rcnt - rcnt_old;
if ((rcnt - rcnt_old) < 0) rcnt_cum += 0xFFFF; // see if counter overflowed
rcnt_old = rcnt;
printf("\nRCnt=%d at %s line %d", rcnt_cum, __FILE__, __LINE__);
Now, every time this function gets called it will spit out a statement saying (roughly) how my rcnt ticks it took:
RCnt=10134 at myprog.c line 123 RCnt=13245 at myprog.c line 123 RCnt=17200 at myprog.c line 123 RCnt=8291 at myprog.c line 123
Now I could make my function optimization (using u_long instead of u_short) and actually tell how much it improved the runtime. First off, here are my "control" values. These are the initial pre- optimization results:
RCnt=225359 at menu/menu.c line 570 RCnt=231900 at menu/menu.c line 570 RCnt=245141 at menu/menu.c line 570 RCnt=156019 at menu/menu.c line 570 RCnt=209051 at menu/menu.c line 570 RCnt=184252 at menu/menu.c line 570 RCnt=147342 at menu/menu.c line 570
The menu I used in all of these tests has seven lines of text. This function gets called once for every line so each of these results represents one line. With that in hand, I then made my change to u_longs. Here's the new code after changing it:
u_long buf1[16][2], buf2[16][2];
u_long val;
.
.
.
for (row = 0; row <= 15; row++)
for (col = 0; col <= 1; col++) {
buf2[row][col] &= val;
buf1[row][col] |= buf2[row][col];
}
And the results:
RCnt=161155 at menu/menu.c line 570 RCnt=163209 at menu/menu.c line 570 RCnt=152278 at menu/menu.c line 570 RCnt=116762 at menu/menu.c line 570 RCnt=151659 at menu/menu.c line 570 RCnt=132341 at menu/menu.c line 570 RCnt=81044 at menu/menu.c line 570
Hmmm, not bad! Comparing with the original values, that got anywhere from 25% to almost 50% improvement. Line 7 in particular benefitted as it went from 147342 to 81044 - a 45% reduction.
Naturally I couldn't stop there. I wondered how much more I could squeeze out. With the root counter code in place it was simple to make a change and immediately see how it affected performance. I next tried unrolling the inner loop. A loop with two iterations isn't terribly efficient. Here's the result:
for (row = 0; row <= 15; row++) {
buf2[row][0] &= val;
buf1[row][0] |= buf2[row][0];
buf2[row][1] &= val;
buf1[row][1] |= buf2[row][1];
}
And the performance results:
RCnt=128559 at menu/menu.c line 570 RCnt=128552 at menu/menu.c line 570 RCnt=119846 at menu/menu.c line 570 RCnt=96861 at menu/menu.c line 570 RCnt=122036 at menu/menu.c line 570 RCnt=106113 at menu/menu.c line 570 RCnt=62157 at menu/menu.c line 570
Ah, good! Another 25% or so shaved off.
Next I removed some spurious DrawSync's. Back when I wrote this function I didn't know when it was necessary to DrawSync and when it wasn't. Now I know better. I removed 3 of the 4 DrawSyncs and got these numbers:
RCnt=122107 at menu/menu.c line 570 RCnt=123124 at menu/menu.c line 570 RCnt=112842 at menu/menu.c line 570 RCnt=91604 at menu/menu.c line 570 RCnt=115285 at menu/menu.c line 570 RCnt=101540 at menu/menu.c line 570 RCnt=59275 at menu/menu.c line 570
Not much, but it's something. Now, since unrolling that inner loop bought me so much I went all the way and unrolled the whole thing. This bloats the code a bit, but let's see how it affects performance. First, here's the new code:
u_long buf1[32], buf2[32];
.
.
.
buf2[0] &= val; buf1[0] |= buf2[0];
buf2[1] &= val; buf1[1] |= buf2[1];
buf2[2] &= val; buf1[2] |= buf2[2];
buf2[3] &= val; buf1[3] |= buf2[3];
buf2[4] &= val; buf1[4] |= buf2[4];
.
.
.
buf2[30] &= val; buf1[30] |= buf2[30];
buf2[31] &= val; buf1[31] |= buf2[31];
Survey says...
RCnt=107402 at menu/menu.c line 598 RCnt=72342 at menu/menu.c line 598 RCnt=97913 at menu/menu.c line 598 RCnt=84892 at menu/menu.c line 598 RCnt=102523 at menu/menu.c line 598 RCnt=90679 at menu/menu.c line 598 RCnt=47420 at menu/menu.c line 598
Yowzah! Line 2 benefitted the most with a 42% drop, but the others fared well too - about 10% across the board.
It was at this point, looking at those 32 lines of code that I realized I could combine each pair of statements into one. That led to this:
buf1[0] |= buf2[0] & val;
buf1[1] |= buf2[1] & val;
buf1[2] |= buf2[2] & val;
buf1[3] |= buf2[3] & val;
buf1[4] |= buf2[4] & val;
.
.
.
buf1[30] |= buf2[30] & val;
buf1[31] |= buf2[31] & val;
The results:
RCnt=97949 at menu/menu.c line 598 RCnt=65920 at menu/menu.c line 598 RCnt=88681 at menu/menu.c line 598 RCnt=77731 at menu/menu.c line 598 RCnt=93839 at menu/menu.c line 598 RCnt=82532 at menu/menu.c line 598 RCnt=43904 at menu/menu.c line 598
Another 10%, wohoo!
Then I began thinking about using the compiler's optimization with the "-O1". I recompiled the whole thing with it on and got these numbers:
RCnt=91048 at menu/menu.c line 598 RCnt=54742 at menu/menu.c line 598 RCnt=88798 at menu/menu.c line 598 RCnt=73330 at menu/menu.c line 598 RCnt=87560 at menu/menu.c line 598 RCnt=78738 at menu/menu.c line 598 RCnt=32243 at menu/menu.c line 598
It occurred to me that the compiler may actually automatically do some of the optimizations I did by hand above. Just for kicks I changed the code back to the original version (the one using u_shorts) and compiled with "-O1". That gave me these results:
RCnt=102868 at menu/menu.c line 603 RCnt=69820 at menu/menu.c line 603 RCnt=100247 at menu/menu.c line 603 RCnt=79537 at menu/menu.c line 603 RCnt=97818 at menu/menu.c line 603 RCnt=87820 at menu/menu.c line 603 RCnt=40535 at menu/menu.c line 603
Not bad actually. For all that work I did hand-optimizing, the compiler was able to almost equal the performance. Still, I don't like depending on the compiler to do the right thing. Plus, my optimizations were a bit better. However, it just goes to show me how good the "-O1" switch does.
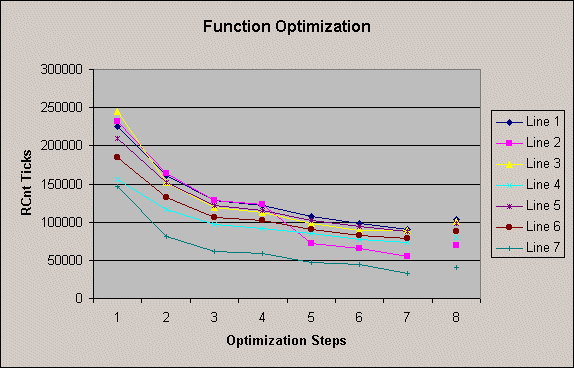
Here's a graph showing all the results. Steps 1-7 correspond to the steps I took above. Step 8 is the results with only the compiler optimization and is good for comparison.
In summary, this was a great learning experience for me. Judging by the final numbers, I was able to speed up the function by at least 50% (in the case of Line 7 it sped up 79%!). I also now have a good way to profile my functions so I can get near-immediate feedback on optimizations I do. I hope it will be somewhat useful to others as well.
This web page and others on this site are © 1998
Scott Cartier
DragonShadow, DragonShadow Industries, DragonShadow Insider, and
Decaying Orbit are ™ Scott Cartier and David Dewitt